Scraping Google search results means collecting result titles, destination URLs, snippets, and positions for a defined set of queries. The reliable approach is API-first: use an approved search API when it covers your use case, then consider HTML collection only when you have permission and can accept changing markup.
Do not start by sending thousands of searches through a large proxy pool. Define the fields, locations, schedule, and retention rules first. Review Google's Terms of Service, keep request volume conservative, and stop when Google returns a challenge or denial rather than trying to automate around it.
This guide builds a bounded Python workflow for scraping Google search results, explains the difference between API and HTML sources, and shows where localization, proxies, parsing, and validation fit.
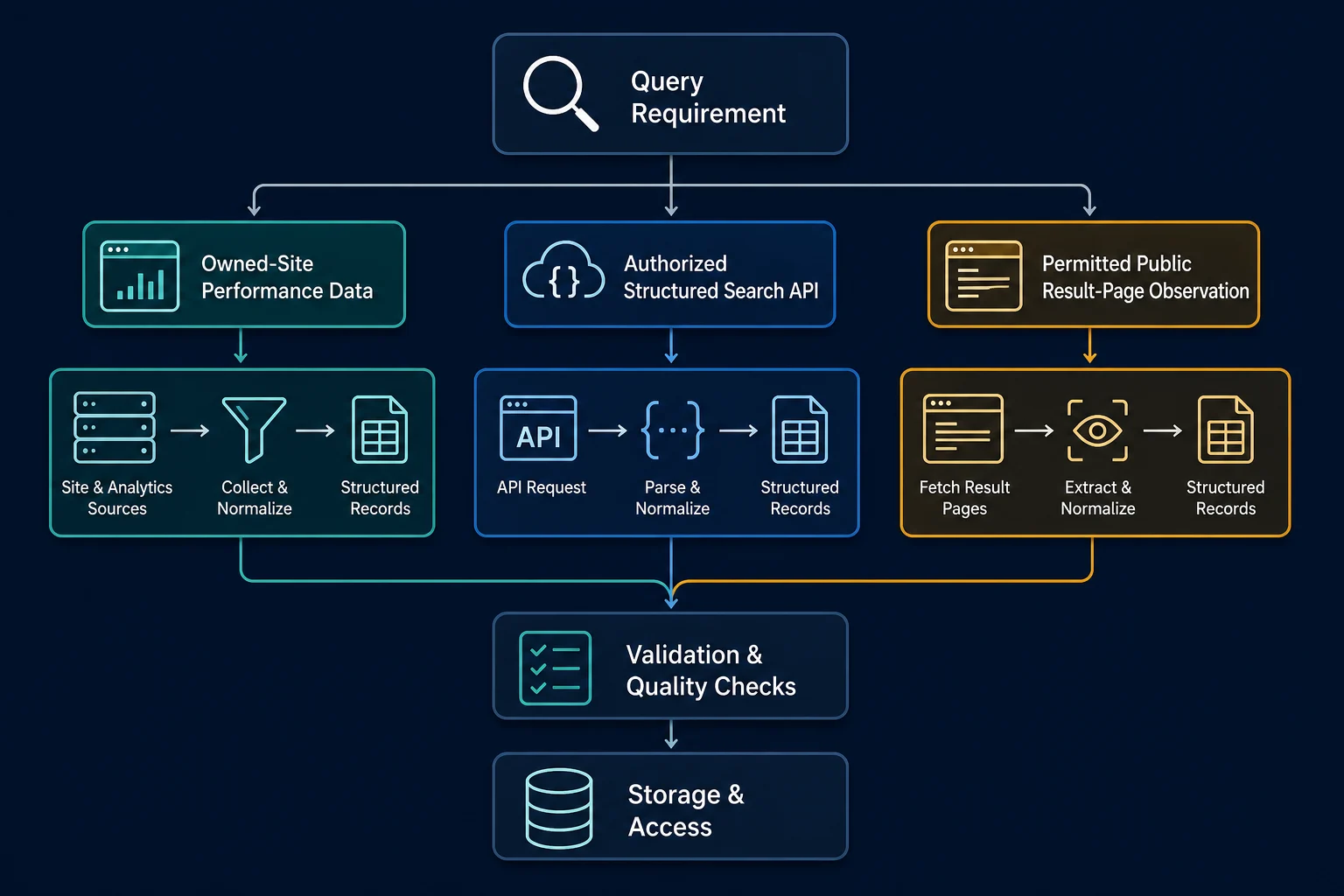
Scraping Google Search Results: Choose the Source
There are three distinct jobs that are often called Google search scraping:
| Goal | Best starting source | Why |
|---|---|---|
| Track how your own site performs | Google Search Console | First-party clicks, impressions, queries, pages, countries, and devices |
| Add search results to an approved application | An authorized search API | Structured data, documented parameters, quotas, and clear error responses |
| Observe the public result page shown to a location | Permitted HTML collection | Captures rendered result-page behavior, but markup and policy constraints are harder |
Search Console is not a general SERP feed. It reports how properties you control perform in Google Search. Google's Search Console documentation describes it as the source of truth for your site's Google Search performance.
Google's Custom Search JSON API can return structured web results for a configured Programmable Search Engine. However, the current API overview says it is closed to new customers and that existing customers must transition by January 1, 2027. Existing customers can still use the example below while planning that migration; new projects need an approved alternative that actually covers their search scope.
Define the Result Schema Before Writing Code
A SERP changes by query, time, language, country, city, device, and sometimes session state. A title and URL without that context are not reproducible observations.
Use a record like this:
{
"query": "example running shoes",
"source": "approved-search-api",
"result_type": "organic",
"position": 1,
"title": "Example result",
"url": "https://example.com/running-shoes",
"display_domain": "example.com",
"snippet": "Example description shown in the result.",
"country": "US",
"language": "en",
"device": "desktop",
"observed_at": "2026-07-04T12:00:00Z",
"collector_version": "serp-v1"
}
Keep organic results separate from ads, local packs, shopping blocks, featured snippets, news, videos, and related questions. Those modules have different shapes and ranking rules. If the project only needs organic links, ignore other modules instead of flattening them into fake organic positions.
Store both the original destination URL and a normalized URL. Remove known tracking parameters for deduplication, but retain the original value for audits. Never use the visible title as a unique key because titles can change between observations.
Use an Authorized Search API When Available
For an existing Custom Search JSON API customer, each request needs an API key, a Programmable Search Engine ID, and a query. Google's REST documentation documents the endpoint and response shape.
Keep credentials in environment variables:
export GOOGLE_API_KEY="replace-with-your-key"
export GOOGLE_SEARCH_ENGINE_ID="replace-with-your-engine-id"
Then request and normalize one page:
import os
from datetime import datetime, timezone
import requests
ENDPOINT = "https://www.googleapis.com/customsearch/v1"
def search(query: str) -> list[dict]:
response = requests.get(
ENDPOINT,
params={
"key": os.environ["GOOGLE_API_KEY"],
"cx": os.environ["GOOGLE_SEARCH_ENGINE_ID"],
"q": query,
"num": 10,
},
timeout=20,
)
response.raise_for_status()
payload = response.json()
observed_at = datetime.now(timezone.utc).isoformat()
return [
{
"query": query,
"source": "google-custom-search-json-api",
"result_type": "organic",
"position": position,
"title": item.get("title"),
"url": item.get("link"),
"display_domain": item.get("displayLink"),
"snippet": item.get("snippet"),
"observed_at": observed_at,
"collector_version": "serp-v1",
}
for position, item in enumerate(payload.get("items", []), start=1)
]
Treat an empty items array as a valid result, not a parser crash. Record quota errors separately from no-result queries. The API's queries.nextPage metadata is safer for pagination than manually guessing the next offset, and the documented API only exposes up to the first 100 results.
Cache repeated query and locale combinations. A retry should not consume another request if the first response was accepted and stored successfully.
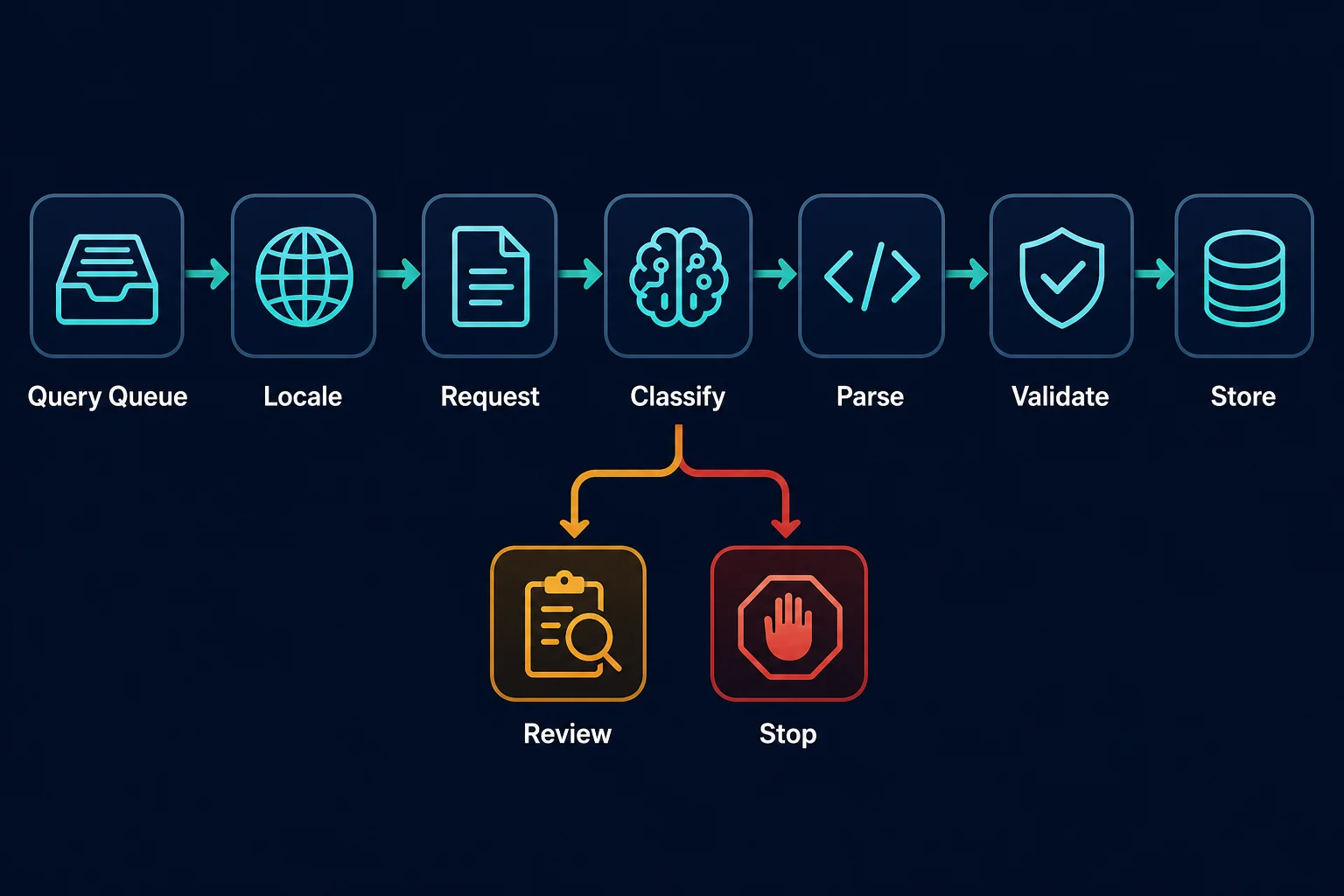
Build a Bounded HTML Collector Only When Permitted
HTML collection is appropriate only when the applicable terms, permission, and project requirements allow it. Google result markup changes, and different page modules do not share one stable selector. A parser copied from a tutorial can silently turn a consent page or challenge into an empty SERP.
Separate fetching from parsing:
- Create a small, deduplicated queue of query and locale combinations.
- Fetch at a conservative rate with a timeout.
- Classify the response before extraction.
- Save a short-lived, access-controlled fixture if your policy permits it.
- Parse only result types your schema supports.
- Validate fields and positions.
- Store the observation with locale and collection time.
The parser should accept HTML as input rather than making its own request. That lets you test selector changes without repeatedly contacting the live service:
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
def parse_organic_results(html: str, query: str) -> list[dict]:
document = BeautifulSoup(html, "html.parser")
if document.select_one("form[action*='sorry']"):
raise RuntimeError("Challenge page received; stop this collection run")
records = []
seen = set()
# Illustrative selectors: verify them against permitted fixtures.
for container in document.select("div:has(> div > a > h3)"):
heading = container.select_one("a > h3")
link = heading.find_parent("a") if heading else None
snippet = container.select_one("[data-sncf], .VwiC3b")
if not heading or not link or not link.get("href"):
continue
url = link["href"]
# Plain HTTP clients often receive Google redirect links; recover the target.
if url.startswith("/url?"):
url = parse_qs(urlparse(url).query).get("q", [url])[0]
# Nested containers can match the same result twice; de-duplicate before
# assigning positions so numbering stays correct.
key = (url, heading.get_text(" ", strip=True))
if key in seen:
continue
seen.add(key)
records.append({
"query": query,
"result_type": "organic",
"position": len(records) + 1,
"title": heading.get_text(" ", strip=True),
"url": url,
"display_domain": urlparse(url).hostname,
"snippet": snippet.get_text(" ", strip=True) if snippet else None,
})
return records
The selectors are deliberately isolated in one function because they are not an API contract. Test the parser against fixtures for normal results, no results, consent, challenge, and unexpected layouts. A zero-record parse on a page that previously produced results should go to review, not overwrite yesterday's dataset.
If fields appear only after browser rendering, use a browser only after confirming the data is absent from the permitted initial response. The Playwright proxy guide explains browser-context isolation; it should not be used to defeat a challenge or access denial.
Preserve Location and Language Deliberately
Search results for the same query can differ by region and language. Record the intended market separately from the actual network exit because they are not interchangeable.
For each observation, retain:
- Country and, if required, state or city.
- Interface and result language.
- Desktop or mobile profile.
- Safe-search and other explicit query settings.
- Proxy region and session identifier, if a proxy is used.
- Timestamp in UTC.
Do not infer location solely from a country-code domain. If the approved source exposes explicit localization parameters, use and record them. For permitted browser observations, keep language, timezone, geolocation settings, and proxy exit geographically consistent.
Run a control query whose regional behavior you already understand. If a US job suddenly returns another market's language or domains, quarantine the batch rather than accepting misleading rankings.
When Proxies Fit Google Search Data Collection
Proxies can provide controlled outbound routing for legitimate localized QA and independent, permitted observations. They do not grant permission, remove quotas, or make high-volume collection acceptable.
Use a residential proxy when a permitted job genuinely needs consumer-region routing at country, state, or city level. Use one sticky session for a browser page and its subresources. Rotate only between independent query tasks, not midway through a rendered page.
Start without a proxy when the API or owned-property source already gives you the required location dimension. Adding proxy infrastructure to an API-key quota does not increase that quota.
If localization requires residential routing, residential proxies support regional targeting and rotating or sticky sessions. The best proxy for web scraping guide compares residential, ISP, and datacenter routes. Test at low volume and use the lightest setup that produces valid observations.
Handle Rate Limits, Challenges, and Failures
Classify the response before retrying:
| Result | Meaning | Action |
|---|---|---|
| Structured API quota error | Key or project quota was reached | Stop, cache, and wait for the documented reset |
| HTTP 429 | Request rate is too high | Honor Retry-After, reduce concurrency, and cool down |
| HTTP 403 | Access, authorization, or policy denial | Stop retries and review the source and permission |
| Consent page | Expected page content was not returned | Handle consent lawfully or exclude that locale |
| Challenge page | Automation was challenged | Stop the run; do not automate challenge solving |
| HTTP 5xx or timeout | Temporary network or service failure | Retry a small number of times with exponential backoff |
| HTTP 200 with zero parsed results | No results or changed/unexpected HTML | Classify the page and send the sample to review |
The HTTP 429 guide covers bounded exponential backoff and Retry-After. Use the delay calculator to check query count, worker count, and pacing before scaling a permitted collection job.
Never retry every failure through a fresh IP. That turns a clear stop signal into more traffic and destroys the evidence needed to diagnose the source, quota, session, or parser.
Validate SERP Data Before Using It
Validation should catch plausible but wrong records:
- The requested query, country, language, and device are present.
- Every organic result has a non-empty title and valid HTTP or HTTPS URL.
- Positions are unique and sequential within one result type.
- Tracking URL normalization does not change the destination host unexpectedly.
- A challenge, consent, sign-in, or error page is never stored as an empty SERP.
- Result count changes beyond a chosen threshold are flagged.
- Parser version and observation time are attached to every record.
Track fetch success separately from data success. A collector with 99% HTTP 200 responses can still be broken if half the pages produce no valid results.
Useful monitoring metrics include accepted observations, quarantined pages, parser-empty rate, 403 and 429 rate, results per query, duplicate URLs, latency, bandwidth, and cost per accepted query. Compare metrics by source, locale, client version, and proxy route.
FAQ
Is scraping Google search results legal?
It depends on the data, jurisdiction, method, contract, permission, and intended use. Public visibility does not by itself answer those questions. Review the applicable terms and obtain legal advice for your project; use an approved API or first-party export when possible.
Does Google have a search results API?
Google documents the Custom Search JSON API for configured Programmable Search Engines, but it is closed to new customers and scheduled for discontinuation for existing customers on January 1, 2027. Search Console APIs provide performance data for properties you control, not general Google results.
Can I scrape Google results with Python requests?
Python requests can fetch permitted HTTP sources and call approved APIs. For HTML, keep fetching separate from parsing, use conservative pacing, classify consent and challenge pages, and expect selectors to change.
Do I need proxies for Google search scraping?
Not for an API that already provides the dimensions you need. Proxies may fit permitted localized result-page observations when the network exit must match a market, but they do not change terms, permissions, or API quotas.
Should I use requests, Beautiful Soup, or Playwright?
Use requests for structured APIs and permitted static HTML, Beautiful Soup for parsing stored HTML, and Playwright only when an allowed field truly requires browser rendering. A browser adds bandwidth, state, and more failure modes.
Conclusion
Scraping Google search results reliably starts with source selection, not selectors or proxy count. Prefer first-party data or an approved API, define one reproducible result schema, and use bounded HTML collection only when it is permitted and necessary.
Record query context, classify every response, validate extracted results, and stop on quotas or challenges. If a legitimate localized observation needs network routing, test a small residential or ISP setup after the data workflow is already correct.