
Ecommerce scraping is the process of collecting structured product data such as titles, prices, availability, ratings, and seller information from online stores. For Amazon, a reliable workflow starts with a narrow list of permitted public pages, fetches them at a conservative rate, extracts only the fields you need, and validates every record before storage.
The difficult part is not downloading one product page. It is keeping product identities stable while layouts, offers, locations, and page states change. Build the scraper as a measured data pipeline, not as a loop that requests URLs as fast as possible.
This guide targets one job: collecting public Amazon product-page data for legitimate research, catalog matching, or price monitoring. Check the applicable terms, robots.txt, and legal requirements before collecting data. Use an official API or licensed feed when it provides the data and usage rights your project needs.
Ecommerce Scraping Workflow for Amazon
A production workflow should separate discovery, fetching, extraction, and validation. That separation lets you reparse a stored response after a selector changes without requesting the page again.
- Define the exact fields and marketplaces you need.
- Build a deduplicated queue keyed by marketplace and ASIN.
- Apply policy, scope, and rate checks before each fetch.
- Fetch one canonical product URL with a bounded timeout.
- Classify the response as a product page, challenge, unavailable item, or error.
- Extract fields into a versioned schema.
- Validate price, currency, availability, and product identity.
- Store the record with its source URL and observation time.
- Schedule the next check according to how quickly that item changes.
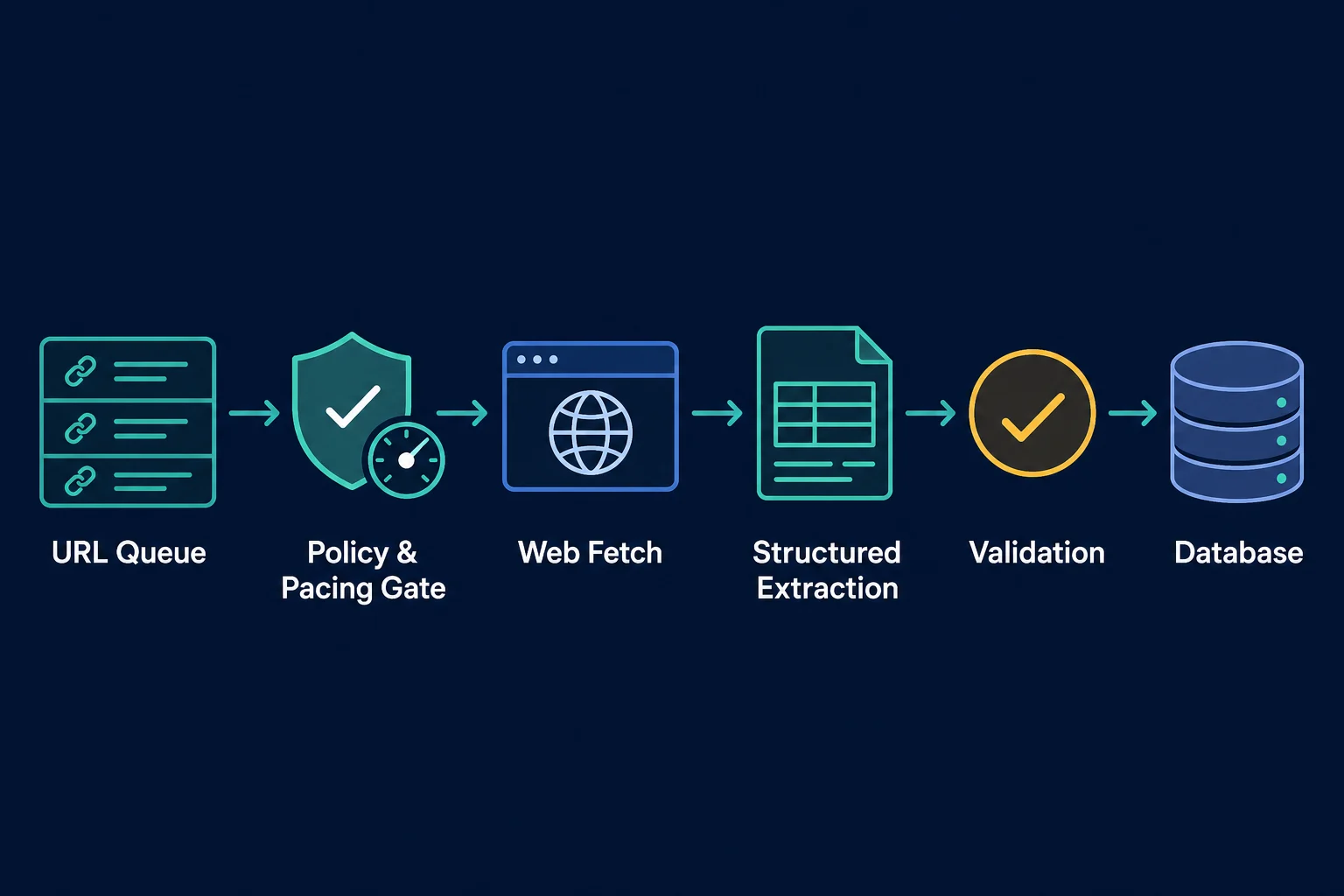
Do not combine all of these stages in one callback. If a page fails validation, you should know whether the fetch returned the wrong page, the parser missed a field, or the source showed a legitimate unavailable state.
Choose the Data Source Before the Scraper
The best source is the one that grants the access and fields you need with the least ambiguity.
| Source | Best fit | Main tradeoff |
|---|---|---|
| Official API or approved feed | Authorized integrations and stable structured data | Eligibility, quotas, field limits, and usage terms |
| Public product HTML | Research or monitoring of a small, permitted page set | Layouts and page states change |
| Browser-rendered page | Fields that appear only after client-side rendering | More CPU, bandwidth, and session complexity |
| Your own seller export | Inventory, listing, and operational reporting | Limited to data your account can access |
Amazon's former Product Advertising API documentation now directs integrations to the Creators API. If an official Amazon program fits your use case, evaluate it before maintaining an HTML parser.
For HTML collection, review the target marketplace's current rules every time the scope changes. The Robots Exclusion Protocol defines how crawlers retrieve and interpret robots.txt, but robots directives are not a substitute for terms, permission, privacy review, or legal advice.
Define a Stable Product Schema
Start with a schema before choosing selectors. A useful minimum record is:
{
"marketplace": "amazon.example",
"asin": "EXAMPLE123",
"canonical_url": "https://www.amazon.example/dp/EXAMPLE123",
"title": "Example product",
"price": {
"amount": 29.99,
"currency": "USD"
},
"availability": "in_stock",
"seller": "Example seller",
"rating": 4.4,
"review_count": 128,
"observed_at": "2026-06-29T12:00:00Z",
"parser_version": "amazon-product-v1"
}
Use the marketplace plus ASIN as the product identity. Do not use a title or a full tracking URL as the primary key. Titles can change, and several URLs can resolve to the same item.
Keep raw display text separate from normalized values. Store "$29.99" if it helps audits, but also parse it into decimal amount 29.99 and currency USD. Never infer a currency from a symbol alone when the marketplace or locale is unknown.
Treat price as a compound observation. A product page can contain a list price, current offer, coupon, subscription price, used offer, shipping charge, or range. Define which price your dataset represents, and record null rather than silently substituting a different offer.
Discover and Canonicalize Amazon Product URLs
Keep discovery bounded. Use an approved seed list, a catalog you are authorized to monitor, or identifiers already present in your system. Avoid turning search results, recommendations, and pagination into an unlimited crawler.
Canonicalize each URL before enqueueing it:
- Normalize the marketplace hostname.
- Extract and validate the ASIN.
- Build one canonical
/dp/{ASIN}URL. - Remove affiliate, referral, session, and tracking parameters.
- Deduplicate on marketplace plus ASIN.
- Reject URLs outside the approved hosts and path patterns.
This cuts repeat traffic and prevents query-string variants from creating duplicate products. It also makes retries safe because the queue has one identity for each item.
Fetch Static HTML or Use a Browser?
Begin with one normal HTTP request. If the response contains the required public fields consistently, a client such as Python requests is easier to operate than a browser.
Use Playwright or Puppeteer only when a permitted field genuinely depends on browser rendering. A browser adds JavaScript execution, subresource requests, cookies, storage, and more failure modes. The Playwright proxy guide covers isolated browser contexts when browser rendering is necessary.
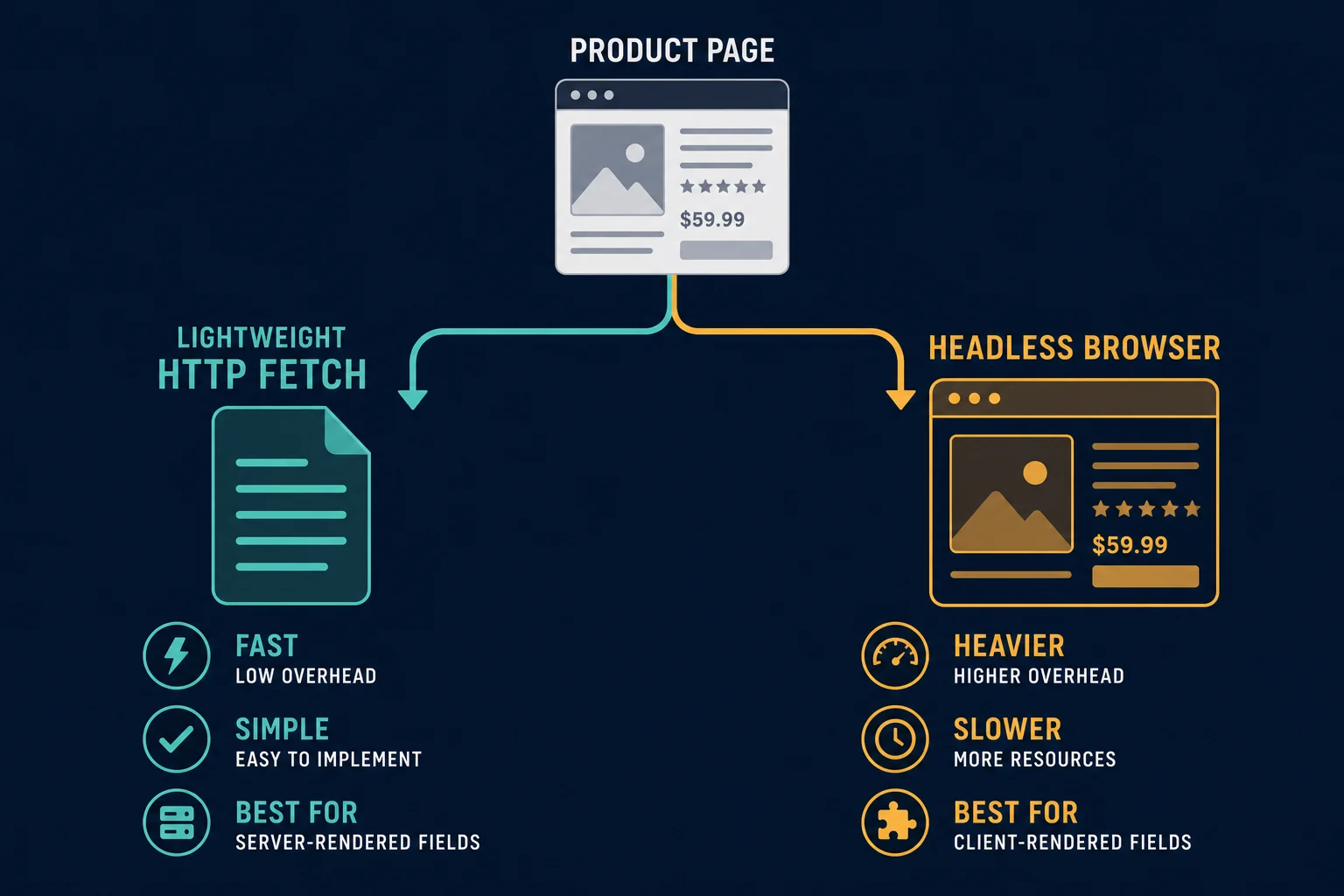
The decision rule is simple:
| Observation | Use |
|---|---|
| Required fields exist in the initial HTML | HTTP client |
| HTML is a challenge, consent page, or error | Stop and diagnose; do not parse it as a product |
| Required permitted fields appear only after rendering | Browser |
| An official API exposes the fields | API |
Do not add a browser merely because one selector broke. First save the response, check its status, identify the page type, and compare it with a known-good sample.
Extract Fields Without Brittle Selectors
Ecommerce layouts change through experiments, localization, device variants, and seller states. One long CSS selector tied to a specific nesting path will fail quietly.
Use a field adapter with ordered, evidence-based strategies:
from dataclasses import dataclass
from decimal import Decimal
@dataclass
class Product:
asin: str
title: str
price: Decimal | None
currency: str | None
availability: str
def parse_product(document, asin: str) -> Product:
title = first_text(document, [
"[data-feature-name='title']",
"h1",
])
price_text = first_text(document, [
"[data-feature-name='corePrice']",
"[data-feature-name='priceBlock']",
])
amount, currency = parse_money(price_text)
availability = classify_availability(document)
return Product(
asin=asin,
title=require_text(title, "title"),
price=amount,
currency=currency,
availability=availability,
)
The selectors are illustrative, not a promise about Amazon's current markup. Inspect pages you are permitted to access, keep fixture samples, and version the adapter when the layout changes.
Prefer semantic containers and structured data over presentation classes when both are available and permitted. Never use regex over the entire HTML to find the first currency-looking string; it may capture a recommendation, coupon, or unrelated offer.
Validate Every Ecommerce Record
Extraction success does not mean data success. A challenge page can return HTTP 200, and a parser can mistake its heading for a product title.
Apply these checks before accepting a record:
- The canonical page identity matches the queued marketplace and ASIN.
- The title is present and within reasonable length bounds.
- Currency matches the expected marketplace or is explicitly recognized.
- Price parses as a positive decimal when the selected offer is available.
- Availability comes from a known state, not arbitrary page text.
- A challenge, sign-in, consent, or error page is not classified as a product.
- The price change is within a review threshold or gets flagged as an outlier.
- The record includes observation time and parser version.
Track field completeness separately from request success. A run with 99% HTTP 200 responses and 40% missing prices is a failed data run.
Store a small, access-controlled sample of source responses for parser tests if your policy permits it. Redact cookies, tokens, personal data, and request headers before saving fixtures.
Handle 403, 429, Timeouts, and Retries
Classify failures before retrying:
| Result | Meaning | Action |
|---|---|---|
| 403 | Access or policy denial | Stop retries; check scope, permissions, request type, and target policy |
| 429 | Request rate is too high | Honor Retry-After, reduce concurrency, and cool down the identity |
| 5xx | Temporary server or upstream fault | Retry a small number of times with exponential backoff |
| Timeout | Network, proxy, browser, or target delay | Retry once after diagnosis; log the failing layer |
| 200 with wrong page | Challenge, consent, redirect, or parser mismatch | Classify the page and quarantine the record |
The HTTP definition of 429 Too Many Requests notes that a response may include Retry-After. Treat that value as a minimum delay. The local HTTP 429 guide covers backoff and concurrency in more detail, while the HTTP 403 guide helps distinguish rate problems from access denials.
Use bounded retries with jitter:
import random
import time
def backoff_seconds(attempt: int, retry_after: int | None = None) -> float:
exponential = min(60, 2 ** attempt)
delay = exponential + random.uniform(0, 1.5)
return max(delay, retry_after or 0)
Do not retry 403 responses in a tight loop or switch identities repeatedly to force access. That creates more traffic while hiding the actual policy, authentication, or page-state problem.
When Proxies Fit Ecommerce Scraping
Proxies are routing infrastructure, not permission. They can support legitimate ecommerce scraping when you need regional price checks, localized availability testing, independent public-page jobs, or stable outbound routing from cloud workers.
Choose the proxy behavior to match the job:
- Use a sticky or static route while one browser session loads a product page and its subresources.
- Rotate between independent public-page tasks, not midway through one page.
- Keep country targeting aligned with the marketplace being measured.
- Record the proxy session, region, response class, and latency for debugging.
- Reduce concurrency and add pacing before increasing pool size.
Rotating residential proxies can help distribute independent, permitted checks across consumer-style networks. ISP proxies fit stable, repeated monitoring where consistent identity and latency matter. The best proxy for web scraping guide compares those options, and residential proxy plans are available when rotation and regional targeting match the workload.
If every route receives the same denial, stop. The issue is probably scope, policy, request behavior, session state, or parser assumptions rather than the number of IPs.
Monitor the Scraper as a Data Product
Operational metrics should reveal whether the web request and the resulting data are healthy.
Track:
- Fetches by HTTP status and classified page type.
- Accepted records and quarantined records.
- Field completeness by marketplace and parser version.
- Median and high-percentile latency.
- 403 and 429 rates per worker and route.
- Price outliers and unexpected currency changes.
- Duplicate ASINs and canonicalization failures.
- Bytes and proxy bandwidth consumed per accepted record.
Alert on changes in ratios, not only total failures. A sudden rise in successful responses with missing titles often means the page layout or response type changed.
Keep a small canary set of stable products. Run it before a large batch, compare the parsed schema with expected ranges, and pause the queue when the canary fails.
Ecommerce Scraping FAQ
Is ecommerce scraping legal?
It depends on the data, jurisdiction, access method, contract terms, and intended use. Public visibility alone does not settle those questions. Review the site's current terms and robots rules, avoid personal or restricted data, and get legal advice for consequential projects.
Does Amazon provide an API for product data?
Amazon provides official programs and APIs for qualifying use cases, subject to eligibility and usage policies. Evaluate the current official option before scraping HTML because API access can provide a clearer contract and structured responses.
Should I use Requests, Playwright, or Puppeteer?
Use an HTTP client when the required public fields are in the initial HTML. Use a browser only for permitted fields that require rendering. Playwright and Puppeteer both work; operational consistency and fixture-tested extraction matter more than the browser library.
How often should prices be checked?
Set frequency from the business requirement and the target's allowed request rate. Fast-changing items may justify more frequent checks, while long-tail products can be refreshed less often. Cache unchanged records and avoid synchronized batches.
Will rotating proxies stop Amazon blocks?
No. Rotation can reduce traffic concentration for independent, authorized tasks, but it does not fix excessive request rates, prohibited access, invalid sessions, bad parsing, or inconsistent browser behavior.
Build Ecommerce Scraping Around Data Quality
Reliable ecommerce scraping is a controlled pipeline: define the Amazon product fields, choose an authorized source, canonicalize ASINs, fetch conservatively, classify page states, validate records, and monitor data quality. Start with a small canary set and expand only when both request health and field completeness remain stable.
If legitimate regional checks need distributed routing, match proxy sessions to the workflow and keep delays conservative. The delay calculator can help size request pacing before you scale workers or proxy capacity.